Cascade LLM

Cascade0 is my first ever LLM, trained entirely on a single RTX 4080 over 1.5–2 weeks. Despite being small (159M parameters), it can complete sentences coherently and correctly. However, due to a training bug, it currently outputs everything in lowercase. Cascade0 predates the idea of the pAI app, but it laid the foundation for everything that followed.
Benchmarks
Here’s how Cascade0 performs against other small models. Trained on 4.8B tokens (~40% of the max 12B), its scores come surprisingly close to models trained on 2T tokens. This demonstrates the efficiency of Cascade’s dataset and training setup.
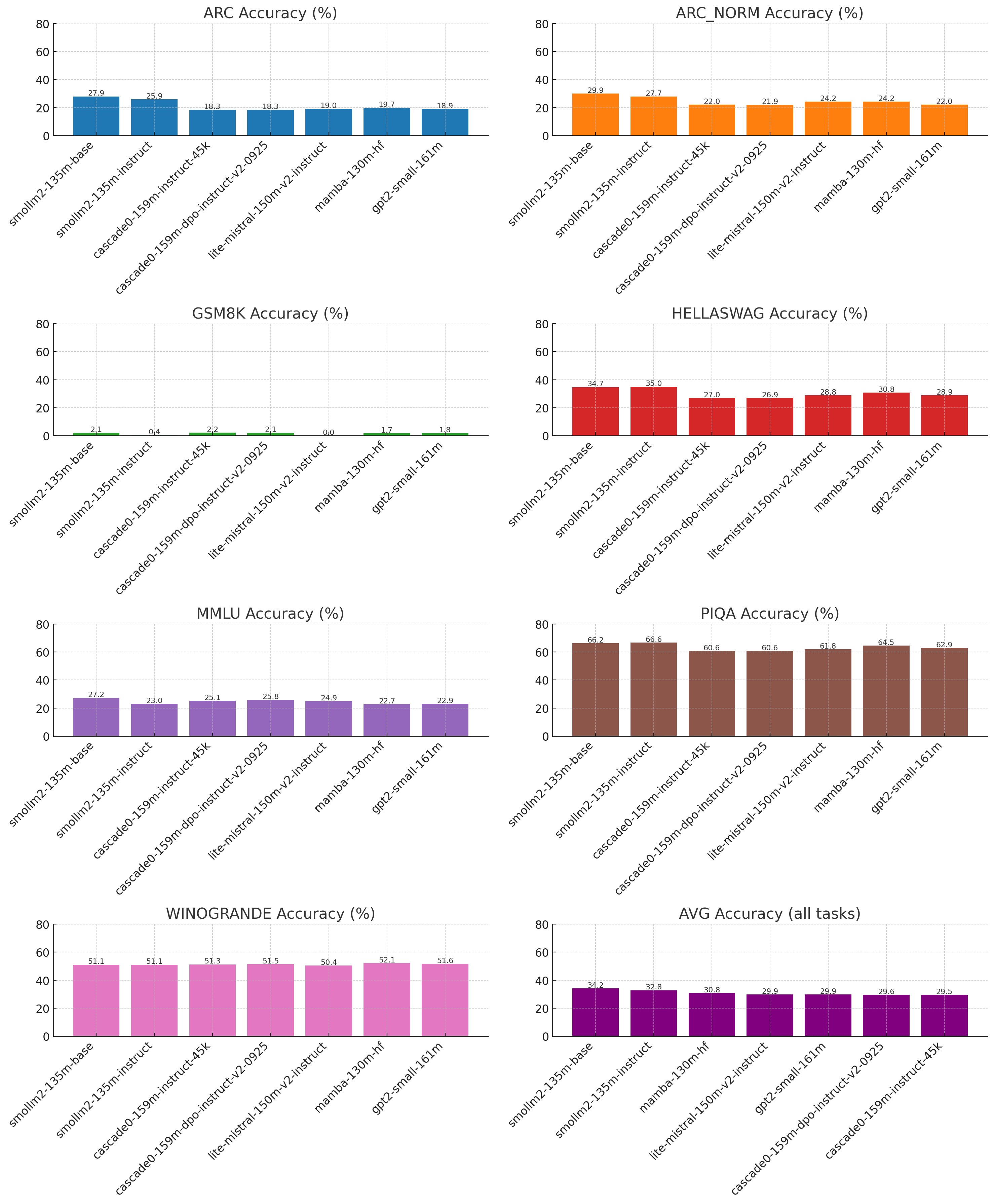
GPT-2 vs Cascade0
Cascade0 (159M) and GPT-2 (161M) are almost identical in size and both tested with F16 quantization. While GPT-2 can handle direct QA (“What’s the capital of France?”), Cascade0 is better at free-form sentence completion and conversational flow. Below are sample comparisons:
